
Developing models for artificial intelligence (AI) involves a combination of mathematics, domain expertise, and computational techniques.
General overview of the process:
1. Define the Problem:
Is it a classification or regression task? Or perhaps a generative task? What are the inputs and desired outputs?
2. Collect Data:
AI, especially deep learning, usually requires large amounts of data. Ensure your data is diverse and representative of the problem you're trying to solve.
3. Pre-process Data:
Normalize or standardize data (for neural networks, it's common to scale inputs to have zero mean and unit variance). Handle missing data. Split data into training, validation, and test sets.
4. Choose a Model:
Start simple. For tabular data, maybe a decision tree or linear regression. For image data, convolutional neural networks (CNNs) are popular. For sequence data (like text), recurrent neural networks (RNNs) or transformers may be suitable.
4. Train the Model:
Use a framework like TensorFlow, PyTorch, Keras, or Scikit-learn. Adjust hyperparameters like learning rate, batch size, etc. Monitor for overfitting: if your model does great on the training data but poorly on the validation data, it's likely overfitting.
5. Evaluate the Model:
Use metrics relevant to your problem: accuracy, precision, recall, F1-score, mean squared error, etc. Evaluate on the test set only once to get an unbiased estimate of real-world performance.
6. Fine-tune & Optimize:
Based on validation results, tweak the model architecture or hyperparameters. Implement techniques like dropout, early stopping, or regularization to combat overfitting if necessary.
7. Deployment:
Once satisfied with the model's performance, it can be deployed to serve predictions in a real-world environment. Ensure the infrastructure can handle the model's computational requirements.
8. Iterate:
Continuously collect new data and feedback. Re-train or update the model as needed to adapt to new data or changing conditions.
Let's tackle a classic problem: Predicting House Prices.
1. Define the Problem:
- Type: Regression (because house prices are continuous values).
- Input: Features of a house (e.g., number of bedrooms, square footage).
- Output: Price of the house.
2. Collect Data:
Use a dataset like the Boston Housing dataset (commonly available). For a real-world scenario, you might scrape real estate websites or use an API.
3. Pre-process Data:
Use Python with the Pandas and Scikit-learn libraries.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# Load data
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['PRICE'] = boston.target
# Standardize data
scaler = StandardScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
# Split data
X = df_scaled.drop('PRICE', axis=1)
y = df_scaled['PRICE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
4. Choose a Model:
For simplicity, let's use a linear regression model.
from sklearn.linear_model import LinearRegression
model = LinearRegression()
5. Train the Model:
model.fit(X_train, y_train)
6. Evaluate the Model:
from sklearn.metrics import mean_squared_error
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error: {mse}")
7. Fine-tune & Optimize:
- You could consider using Ridge or Lasso regression for better regularization.
- Use grid search or random search to optimize hyperparameters.
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
parameters = {'alpha': [1e-15, 1e-10, 1e-8, 1e-4, 1e-3, 1e-2, 1, 5, 10, 20]}
ridge = Ridge()
ridge_regressor = GridSearchCV(ridge, parameters, scoring='neg_mean_squared_error', cv=5)
ridge_regressor.fit(X_train, y_train)
print(ridge_regressor.best_params_)
8. Deployment:
Use Flask or FastAPI for a simple API.
# app.py
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json()
input_data = [data[col] for col in boston.feature_names]
prediction = model.predict([input_data])
return jsonify({'prediction': prediction[0]})
if __name__ == '__main__':
app.run()
To run the Flask app:
$ flask run
9.Iterate:
Continuously collect new house price data. Re-train the model with the updated data to ensure it remains accurate over time. This is a simplified example to illustrate the process. In a real-world scenario, each step may require much more attention to detail, especially when it comes to data preprocessing and model fine-tuning.
AI models can be categorized by the tasks they're designed to handle. Here's a breakdown:
1. Supervised Learning:
Classification:
Binary Classification (two classes):
- Logistic Regression
- Support Vector Machine (SVM) with a linear kernel
Multi-class Classification (more than two classes):
- Softmax Regression (Multinomial Logistic Regression)
- Support Vector Machine (SVM) with non-linear kernels (RBF, Polynomial, etc.)
- Decision Trees and Random Forests
- Gradient Boosted Trees (XGBoost, LightGBM, CatBoost)
- Neural Networks (Feed-forward, CNN for image classification, etc.)
Regression (predicting continuous values):
- Linear Regression
- Polynomial Regression
- Support Vector Regression
- Decision Trees and Random Forests for regression
- Neural Networks
- Ridge/Lasso Regression
2. Unsupervised Learning:
Clustering (grouping data points):
- K-Means clustering
- Hierarchical clustering
- DBSCAN
- Gaussian Mixture Model
- Dimensionality Reduction (reducing the number of features or data point dimensions):
- Principal Component Analysis (PCA)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Linear Discriminant Analysis (LDA)
- Autoencoders (neural network based)
Association (discovering interesting relations between variables):
- Apriori
- Eclat
3. Semi-Supervised and Self-Supervised Learning:
Semi-supervised (mix of labeled & unlabeled data):
- Label Propagation
- Label Spreading
- Self-training
Self-supervised (creating pseudo-labels from data):
- Contrastive learning
- Denoising Autoencoders
- Predictive coding
4. Deep Learning:
Image Data:
- Convolutional Neural Networks (CNNs)
- Transfer Learning (using pre-trained models like VGG, ResNet, etc.)
Sequence Data:
- Recurrent Neural Networks (RNNs)
- Long Short-Term Memory networks (LSTM)
- Gated Recurrent Units (GRU)
- Transformer architecture (BERT, GPT, T5 for NLP tasks)
Generative Models:
- Generative Adversarial Networks (GANs)
- Variational Autoencoders (VAE)
- Reinforcement Learning:
- Q-learning
- Deep Q Network (DQN)
- Policy Gradient Methods
- Actor-Critic Methods
5. Reinforcement Learning:
- Learning how to act to maximize a reward:
- Value-based: Q-learning, Deep Q Network (DQN)
- Policy-based: Policy Gradients
- Model-based RL
- Actor-Critic: A3C, A2C, etc.
This is by no means an exhaustive list, and the boundaries between these categories can sometimes blur.
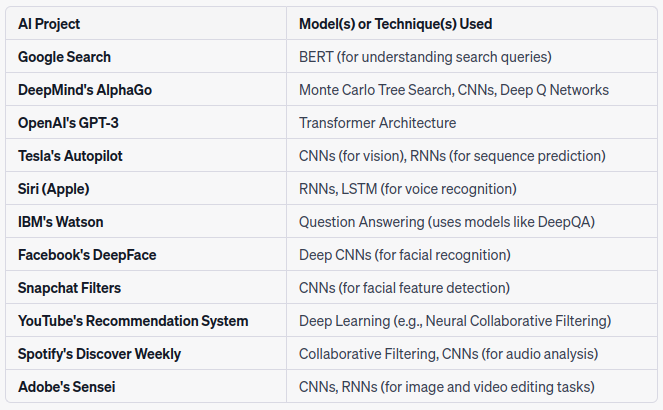
Here's a table showcasing a selection of well-known AI projects and the models or techniques they are based upon.
However, do note that many AI projects use a combination of multiple models and architectures, and this list is just a simplified representation
'%3e%3cellipse%20cx='508.5'%20cy='387.5'%20rx='324.5'%20ry='234.5'%20fill='url(%23paint0_linear_74_1900)'/%3e%3c/g%3e%3cdefs%3e%3cfilter%20id='filter0_f_74_1900'%20x='0'%20y='-31'%20width='1017'%20height='837'%20filterUnits='userSpaceOnUse'%20color-interpolation-filters='sRGB'%3e%3cfeFlood%20flood-opacity='0'%20result='BackgroundImageFix'/%3e%3cfeBlend%20mode='normal'%20in='SourceGraphic'%20in2='BackgroundImageFix'%20result='shape'/%3e%3cfeGaussianBlur%20stdDeviation='92'%20result='effect1_foregroundBlur_74_1900'/%3e%3c/filter%3e%3clinearGradient%20id='paint0_linear_74_1900'%20x1='227.37'%20y1='272.209'%20x2='619.387'%20y2='679.264'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%23863CF9'/%3e%3cstop%20offset='0.239583'%20stop-color='%23B887F4'/%3e%3cstop%20offset='0.494792'%20stop-color='%239FB4FC'/%3e%3cstop%20offset='0.776042'%20stop-color='%23B7E4BB'/%3e%3cstop%20offset='1'%20stop-color='%23FCFD64'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)